It started as a Schlager idea:
"a German song about today's news." A tooling-research chat turned
into a genre pivot, a casting round, and finally a whole pipeline.
Spark · Research
"A German Schlager about today's news"
The first question was pure tooling research: which AI tools for
text → music → video? Answer stack: news & lyrics right in the chat,
Suno for the song, Veo/Kling/Seedance for video, FFmpeg for the cut.
"I'm thinking about creating a german schlager song about today's news with ai tools, potentially including a video."
Subject · The News
The collapsed €1000 energy rebate
Picked from the day's headlines: the Bundesrat blocks the promised
tax-free €1000 rebate. A perfect Schlager arc — anticipation →
disappointment → we dance anyway. "Everyone has an electricity bill."
⚡ The Pivot · Genre Switch
Schlager → late-90s Deutschrap
The decisive creative leap. First Schlager-pop, then the voice
trimmed to a "gentle-giant baritone" — then the full genre pivot to
Fanta-4-/Fettes-Brot-/Beginner boom-bap, 90 BPM, rapped verses with
a sung hook. Lyrics and Suno prompt rewritten from scratch.
"and now as a german rap style of late 90s early 2000s"
Casting · The Character
A Yeti named Helmut
Four mascots evaluated. The Yeti wins for two reasons: the cold
metaphor (a Yeti freezing because of his electricity bill = peak
Schlager self-irony) and the AI trick — white fur on any
background = high contrast = models keep him consistent. The name
"Helmut": a warm German everyman-uncle name that carries both
framings — Schlager Heimat vibe and Deutschrap blue-collar.
Trick · Continuity
The edelweiss medallion
The genre pivot swapped the wardrobe entirely:
Trachtenjanker → oversized burgundy hoodie + DJ headphones. To keep
it the same Helmut, a tiny edelweiss medallion travels along
as a signature — "still Helmut, just remixed."
Architecture · Pipeline
Driven from Claude Code
Final research step: how do you drive this from Claude Code?
Result — an MCP gateway for the models, scenes.json
as single source of truth, scripts for generate / lip-sync / compose.
Exactly that structure is in the repo today.
Maximally German — but proportions tricky for AI video.
3.
🐻❄️
Polar bear "Eberhard"
Same cold logic, but the Knut trope is used up.
WC
🌭
Caretaker dachshund
Very German — dogs drift harder in AI than blob creatures.
Creative DNA
What fed what
Topical, musical, linguistic — the influences behind
every line.
📰 TOPICAL · HEADLINES FROM MAY 12, 2026
HEADLINEBundesrat blocks the tax-free €1000 energy rebate; coalition committee meets that evening
→
central narrative arc · "die Tausend bleiben Eis"
HEADLINEMerz's reform agenda stuck in federal gridlock
→
"Friedrich Merz hat 'nen Plan, doch der Plan hat 'nen Plan"
HEADLINESPD / CSU / CDU committee squabbling
→
"reden, reden, reden — doch am Ende kein Beschluss"
REJECTEDCybercrime / AI driver · doctors' congress protests
✕
weaker Schlager arc — no "dance anyway"
🎧 MUSICAL FAMILY TREE
SCHLAGER · DRAFT 1 · REJECTED
Helene Fischer · pop polishMickie Krause · beer-tent energyAndreas Gabalier · folk-rock baritoneHansi Hinterseer · alpine warmth
⚡ GENRE PIVOT ⚡
DEUTSCHRAP · DEVELOPED
★ Fanta 4 — "MfG" · bureaucracy-satire template★ Fettes Brot — "Jein" · narrative + melodic hookBeginner · Hamburg boom-bap, Rhodes, upright bassFreundeskreis — "ANNA" · jazzy bridgeEins Zwo · dense internal rhymeSamy Deluxe · sharper sound optionSmudo / Thomas D · König Boris · vocal character
Suno filters real artist names inconsistently → the
prompt translates them into sonic descriptors: "jazzy boom-bap, 90 BPM
dusty drums, mellow Rhodes, warm upright bass, vinyl crackle, scratches."
🗣️ LANGUAGE FORENSICS
„Pustekuchen"
Peak boomer brush-off ("no chance") — fits the bureaucracy mockery.
„Tinnitus"
Ringing, then gone — abstract Eins-Zwo/Dendemann wordplay.
"Pustekuchen" + "Föderalismus" (bureaucratese) in one verse = a Fanta-4/Fettes-Brot signature.
The Mixing Desk
Hear the pivot — live
Three versions of the same song, one playhead. Click a
track or drag the crossfader and blend between them live — the
position keeps running, like a DJ rig.
DECK A
Female
Schlager · Draft 1
DECK B
Male
Schlager · Gentle Giant
DECK C
HipHop
Deutschrap · Final
◀ FEMALEMALEHIPHOP ▶
0:000:00
90 BPM
A & B are the rejected Schlager drafts · C is the final version in the video
The Result
"This morning, the power bill came."
Three pages long. Then hope from Berlin — until the
Bundesrat blocks it. The Tagesschau turns into a boom-bap track in the
spirit of Beginner, Fettes Brot & Fanta 4.
The Pipeline
From news ticker to music video
Every step driven from Claude Code — Atlas Cloud as the
primary model gateway, fal.ai for lip-sync.
01
📝
Concept & Lyrics
Story, rhyme, timing mapped to 90 BPM.
creative/lyrics.lrc
02
🎵
Suno Track
Deutschrap beat, 3:53, hand-curated.
tausend_euro.mp3
03
🧊
Helmut Reference
8 variants + 3 angles locked.
nano-banana 2
04
🎞️
21 Scenes
Ref-to-video, 1 take each.
Seedance 2.0 · Atlas
05
👄
Lip-Sync (trialed)
Experimentally tested only — not in the final cut.
Hedra · fal.ai
06
🎚️
FFmpeg Cut
On the beat, VHS grade, 1080p.
preview.mp4
assets/helmut_ref.png · the canonical reference
The Character
Helmut — the Yeti MC
Consistency is non-negotiable. Four anchors are forced
into every prompt — they travel through every generation.
🟥
Burgundy hoodieThe most important visual lock — slightly faded, lived-in.
❄️
White-blue furNever grey, never pure white — faint ice-blue highlights.
🌼
Edelweiss medallionThe continuity trick since the Schlager version.
🚫
No fangsAlways in the negative prompt. Gentle giant, not a monster.
The Storyboard
21 scenes, one pass
Each tile = a real frame from the generated clip,
time-locked to the lyrics.
The Lab
Most of it was experiment
The concept doc was written before we touched the
API. Almost every assumption was wrong on first contact. A field log:
LOG 01 · MODEL BAKE-OFF: VEO → KLING → SEEDANCE
Three models tried. Veo 3.1 drifted (face went
humanoid) and actually cost $0.20/s instead of the assumed $0.03 —
abandoned. Kling o3 Pro held the character (16 clips, 3–4 takes/scene)
but pricey. Seedance 2.0 became the production model: the only one
that renders legible German text on CRT screens, ID cards and bills.
Kling o3 Pro · v1 batch
Good consistency, $12.16 for 16 clips, 3–4 takes per scene — dropped in favor of Seedance.
Seedance 2.0 · production
Best German text rendering, one take per scene, 21 scenes final.
LOG 02 · CONCEPT vs. REALITY
✗ ASSUMPTION
Atlas catalog lives at /v1/models
✓ REALITY
That's only the OpenAI-compatible text route (105 models). The real catalog (313 models: Veo, Kling, Seedance…) is at /api/v1/models.
✗ ASSUMPTION
3:00 minutes, timings from the concept
✓ REALITY
Suno delivered 3:53. All scenes re-timed against the real LRC boundaries — v1 (scene_01–09) → v2 (scene_a01–a21).
✗ ASSUMPTION
One reference is enough for consistency
✓ REALITY
With just 1 ref the face drifts humanoid/baboon-ish. Fix: 1 anchor + 3 angles (face/profile/back) + compact bible + hard negatives.
✗ ASSUMPTION
Catalog prices are accurate
✓ REALITY
Seedance bills token-metered ≈ 2.17× the catalog rate. Veo $0.20/s instead of $0.03. Budget raised after the lesson.
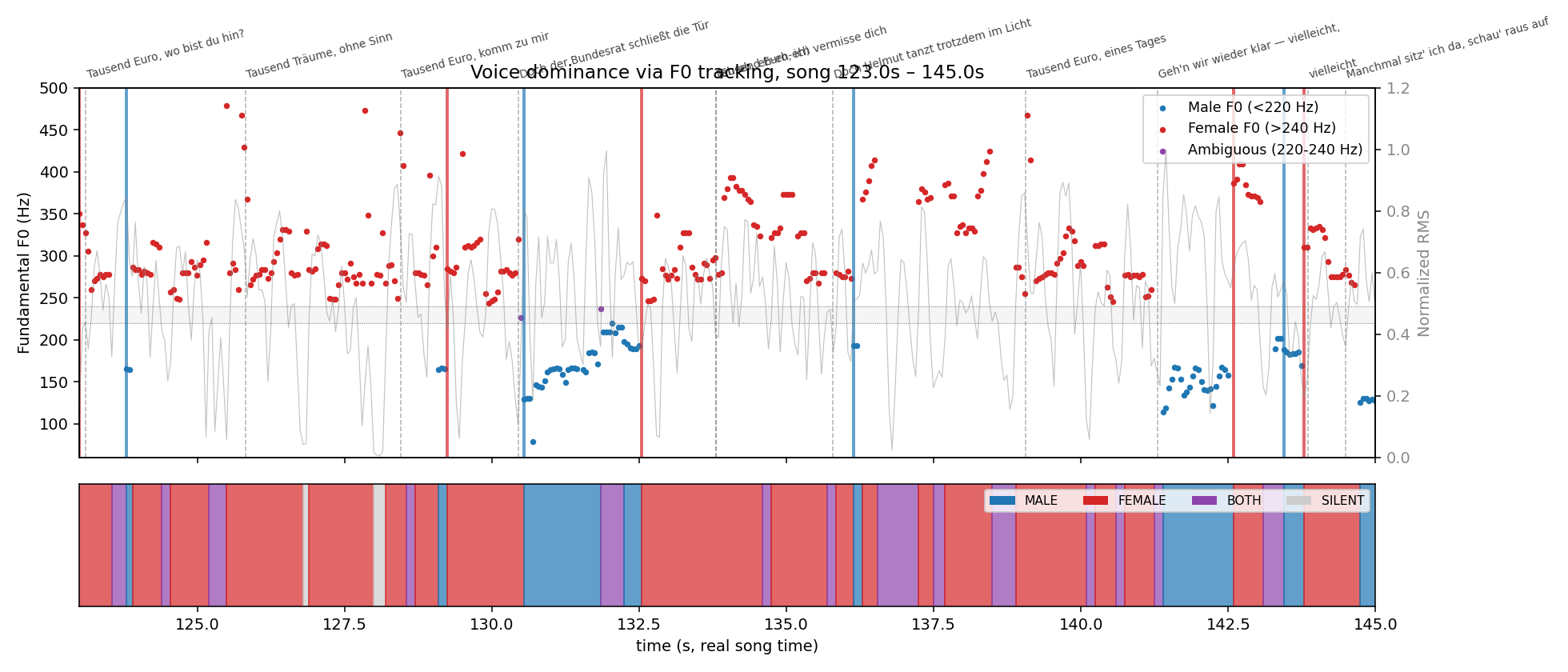
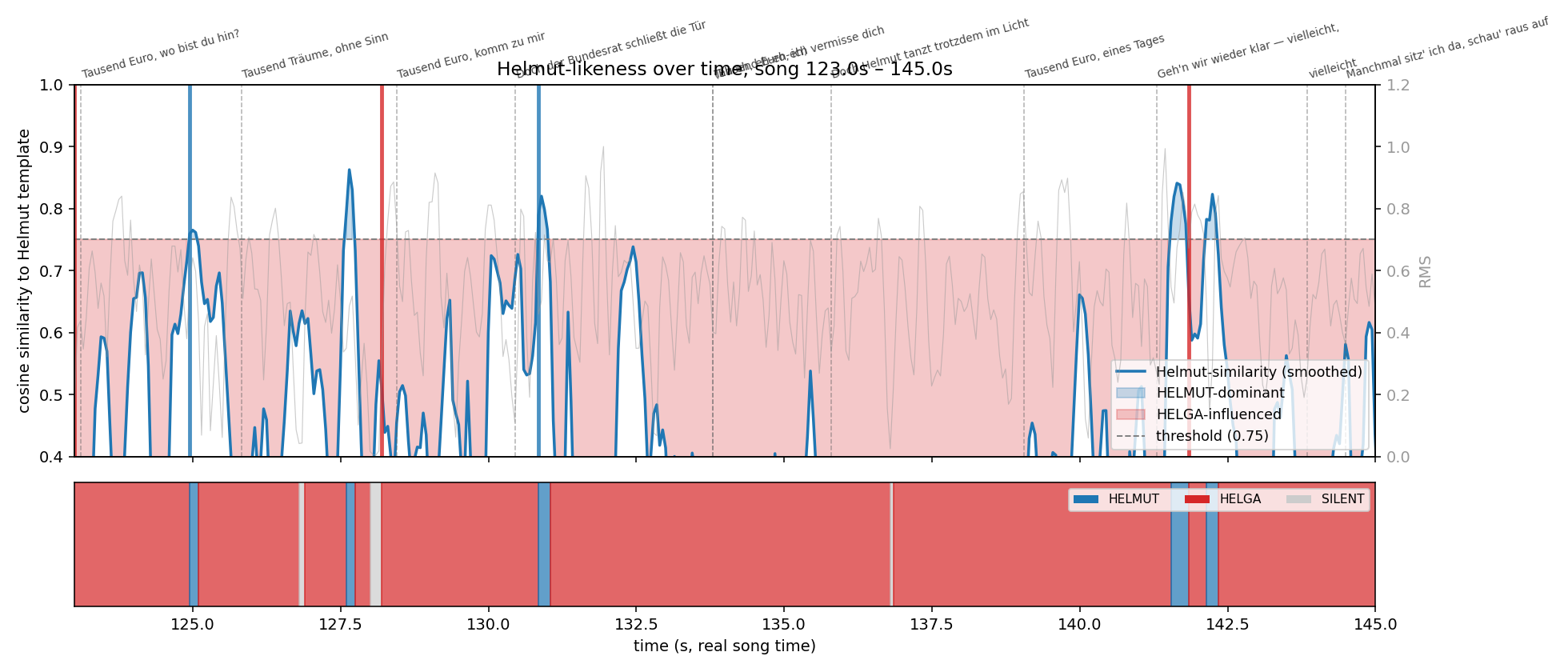
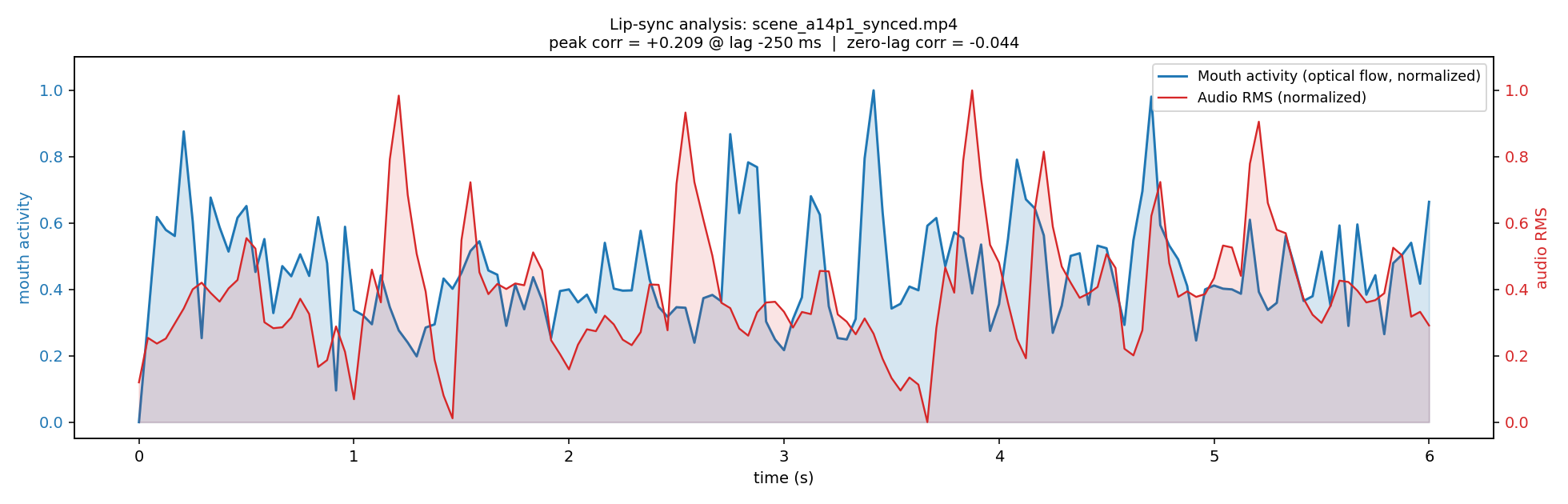
LOG 03 · LIP-SYNC ATTEMPTS
No Atlas model auto-syncs to a provided audio track. So
external trials — MuseTalk vs. sync v3 vs. Hedra
Character-3 (fal.ai) — plus custom audio analysis: MFCC template,
voice and timbre charts to verify alignment.
Outcome: never produced. The final cut uses Seedance's native
rap-cadence mouth motion — true lip-sync stayed experimental.
Real sync outputs from the trials — one shows the
classic MuseTalk problem (artifacts around the mouth & fur on
stylized faces); the v3-pass close-ups hold up usable. Sound on for the
sync impression:
The hook has a female harmony behind Helmut's lead. So
the screen wouldn't show Helmut miming someone else's voice, Helga
was added — a second Yeti character (red beanie, corduroy bomber, the same
edelweiss medallion as a continuity anchor). But the moment two
characters sing in one scene, you get two simultaneous lip-sync
targets plus voice attribution — too error-prone with single-character
sync already unsolved.
Helga · the second voice
Own character for the hook harmony. nano-banana, 6 variants + outfit tests.
Two characters, one scene
Double lip-sync + "who sings which line" — unstable without very short cuts & detailed planning.
Decision: Helga removed for now — good enough for
now, final cut is Helmut only. Way forward: more thorough planning
& shorter cuts — or simply different shots where Helmut is not on
screen during the second-voice lines (environment / B-roll), which removes
the two-character problem entirely.
⚠ WAR STORY · GHOST SPEND
How a 900-second timeout burned ~$30
Seedance 2.0 occasionally takes 15–25 minutes for a 13–15s clip.
The original poller gave up after 900s (15 min); the retry loop
submitted a new generation (~$3) — up to 4×. Server-side, the
original prediction kept rendering and would have finished.
Atlas has no cancel endpoint. Effect: ~$15 burned per
scene-that-would-have-worked-anyway. Hit A13 & A14.
→ Fix: timeout raised to 1800s (30 min). Waiting is the only cancel option.
The Tools
The Models — and our verdict
Which AI model did what, what it cost, and why it won or
got cut. External figures as of May 2026; "verdict" = what actually
happened in this project.
🎬 VIDEO
Veo 3.1DeepMind
Best prompt adherence — but Helmut's face drifted humanoid, and the priciest. Tested, dropped.
~$0.40/s standard · 8-s clips · still "Preview"
Kling 3.0 ProKuaishou
Held the character well — the v1 path (16 clips, $12.16). Too costly at volume → replaced.
All Helmut/Helga refs + cover, thumbnail, OG (CLI). Best legible in-image text.
~$0.067/image · refuses real-person photos → blocked the ESC composite
Imagen 4 UltraDeepMind
Text-to-image only, no reference input → couldn't lock Helmut, produced a generic yeti.
$0.06/image · max 2K · wrong tool for consistency
Seedream v4.5ByteDance
Multi-ref edit (up to 10): for the ESC special it took the real photo + Helmut where Gemini refused.
~$0.03–0.036/image · strong identity preservation
Grok ImaginexAI
Also multi-ref with the real photo — gave the closest ESC costume silhouette of any editor.
$0.02/image std · $0.07 pro
👄 LIP-SYNC
Hedra Character-3Hedra
Benchmark for stylized faces — the reason fal.ai stays installed (Atlas doesn't host it). Trialed, never shipped.
credit sub ~$10/mo+ · per-second via fal.ai
MuseTalk 1.5Tencent · OSS
Artifacts around mouth & fur on Helmut's face — the "Tiefpunkt" in the making-of. Rejected.
free (self-host) · 256×256 mouth region
sync.so v3sync. labs
The "sync v3" trials — the a14 close-ups were "usable", the best of the lip-sync attempts. Not final.
~$0.04–0.13/s by model · sync-3 = 4K
🎵 AUDIO
Suno v5.5Suno, Inc.
★ THE SONG
Made the track. Drove the Schlager→Deutschrap pivot + the 3 versions. No official API → manual.
v5.5 · 26 Mar 2026 · consumer subscription
ElevenLabs v3ElevenLabs
★ NARRATOR
The making-of narrator ("George", locked voice_id) with per-line emotion tags. Free tier blocks cloning → premade voice.
v3 GA 14 Mar 2026 · Starter $5/mo unlocks cloning
🛰️ GATEWAYS
Atlas Cloudprimary gateway
~95% of all generations. Gotchas: the real catalog is /api/v1/models; no cancel endpoint → ghost-spend; catalog prices are lower bounds.
300+ models · ~30–54% cheaper than fal.ai (vendor-stated)
fal.aisecondary
Kept only for Hedra lip-sync — everything else routes through Atlas (cheaper).
1000+ models · per-output or GPU-second
Sources & detail: MODELS.md in the repo. Empirical figures (≈2.17×, $12.16, …) from cost_log.csv.
The Bill
What does an AI music video cost?
$63
LOGGED // 40 API CALLS
~$90
REAL // INCL. GHOST SPEND
$50
SEEDANCE 2.0 // PRODUCTION
$0.80
ALL CHARACTER REFERENCES
Seedance 2.0 · 21 scene videos (Atlas)$50.06
Kling o3 Pro · v1 test batch (dropped)$12.16
Ghost spend · A13/A14 timeout retries~$27
nano-banana · Helmut/Helga references$0.80
The original budget was $25. It was deliberately raised
after we learned Seedance bills ~2.17× the catalog rate — and that too
short a timeout is more expensive than patience.